Lev Goncharov
Infrastructure simplifying engineer
Agreements as Code: как отрефакторить инфраструктуру и не сломаться

Date: 2020-10-09
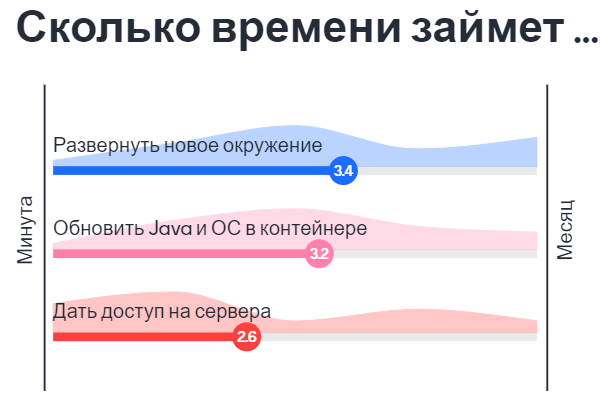
Здесь расшифровка выступления на TechLeadConf 2020-06-09. Прежде чем начнем, попробуйте ответить для себя на вопрос какие у вас ожидания от взаимодействия с инфраструктурой? Например сколько времени займет:
- Развернуть новое окружение для тестов.
- Обновить версию java и/или ОС внутри контейнера.
- Выдать права доступа на сервер.
Спойлер результатов опроса во время TechLeadConf:
! Menti
{kind=link}

А теперь умножьте свои ожидания на двое, и вы получите суровую реальность. Не приятненько как-то, да? Особенно когда ты тот самый человек со стороны инфраструктуры, который говорит, что всё будет долго. Но так долго не потому, что я такой-сякой чопорный. Для этого, как правило, есть объективные причины. Давайте разбираться почему так происходит и что с этим делать.
Инфраструктура как она есть
Cлучайности + Договоренности + Процессы = Инфраструктура

Прежде чем ответить на вопрос почему так долго? Предлагаю разобраться с тем что такое инфраструктура и как она появляется. Зачастую, процессы появления инфраструктуры изоморфны и похожи между собой. Рассмотрим собирательный образ некого сферического коня, не проводящего в вакуме: появления инфраструктуры для разработки коробочного приложения.
- Случайность. Есть приложение. Но оно не появляется просто так, его разрабатывают вполне конкретные люди. Со временем или сразу появляется потребность развернуть/запустить приложение где-то(Спасибо Кэп!). В нашем случае лет 10-15 назад было отправлено письмо с просьбой смонтировать сервер в стойку. У кого-то это просьба в телеграмм чате настроить сервер. Суть в том, что инфраструктура это про то, что вас кто-то что-то попросил сделать, развернуть сервис. Изменения не происходят потому что вам так захотелось, за изменениями стоят люди.
- Договоренности. Со временем, случайные запросы на изменения через jira, email, slack могут перерасти в хаотичный поток запросов. В нашем случае необходимо было разворачивать множество окружений похожих на клиентские. Но бывает можно услышать “если хотите ускорить развёртывание, то не пишите нам в четверг, потому что мы ходим в серверную по средам”. Появляются договоренности.
- Процессы. Апогеем становится преобразование договоренности в процесс. Появляется формальный процесс: заведите таску в jira, заполните необходимые поля и в течение 7 дней первый освободившийся инженер создаст вам новое окружение.
Инфраструктура стремится к хаосу

Как вы понимаете, монтаж серверов в стойку, процесс не быстрый, а разработка должна лететь. Но всё меняется, и приложение было контейнеризировано. Появилась возможность создавать динамически виртуалки на CoreOS и запустив compose файл получить окружение похожее боевое. Этакий k8s на минималках. И тут появился первый звоночек: а кто отвечает за YML файлике в git? Кто описывает инфру? Закономерно, код без присмотра начинает дурно пахнуть и привет групповая безответственность. Растет технический долг за счет быстрых и незаменимых подпорок из велосипедов. Меняется команда с одной стороны, потом с другой. И всё. Приплыли. Наступает ОПА момент - когда инфраструктура работает, но никто не видит картинку целиком и не понимает почему она работает именно так. Это ни хорошо и ни плохо. Это данность: Инфраструктура стремится к хаосу, как и наша вселенная стремится к тепловой смерти.
Как бороться с Хаосом?
Бумажки и инструкции на защите от хаоса

Написать инструкции может прийти первым на ум, когда вы захотите бороться с хаосом. У меня тут есть, забавная история, как в одной ооооочень большой организации любили писать бумажки почти на каждый чих. Однажды, там для переезда сервиса согласовали временную схему сети на пару недель и выставили сервис в интернет. Соль в, том что я нашел это спустя пять лет. А на минутку это: нефтебаза… в аэропорту… с доступом в сеть ЦОД. Не хорошо как-то. Бумажка есть, а реальность показывает другое.
Agreements as Code

Аналогичная ситуация будет с задачами в Jira. Вас попросили, подготовить новое окружение. Вы что-то сделали и забыли как-оно там было настроено. Но если те же договорённости формализовать в виде кода. Пусть даже на своем DSL, или просто кодом на Ansible написали. Итогом у вас есть воспроизводимое решение и единая точка правды. Кто-то то поправил код в репозитории и вот обновленная версия приложения уже в проде. Но стоит ли это все эти договоренности автоматизировать? Стоит ли овчинка выделки?
Agreements as Code внедрять нельзя забить

Для ответа на вопрос автоматизировать или нет процесс/договоренности я выработал матрицу для принятия решений. Она концептуально похожа на матрицу Эйзенхауэра.
- *ОПА - степень “проблемности” проблемы. Насколько вы/ваши коллеги/заказчики страдаете.
- Стоимость решения - сколько времени/денег стоит решить проблему.

Рассмотрим краевые случаи:
- Проблема огромная, решается дешево - надо делать. Инструкция по заведению пользователей из confluence который пользоваться каждый день, замечательно заменяется скриптом, который формализует договоренности.
- Проблема маленькая, решается дешево - спорно, делать по остаточному принципу. Разбираться с REST api редкого сервиса, чтобы раз в год обновить DNS может быть не лучшим выбором для инвестиции времени. Но на долгой дистанции может пригодиться.
- Проблема маленькая, решается дорого - игнорировать. Как часто вам приходится обновлять подпись к email? раз в год? в три?
- Проблема огромная, решается дорого - спорно, необходимо десять раз подумать, т.к. без опыта можно сделать только хуже. Например, скриптики которые автоматизировали процессы и договорённости вдруг стали стандартом, все пользуют и не знают как оно работает. Собственно, та самая *ОПА когда вам надо рефакторить IaC.
Ручной труд -> Механизация -> Автоматизация

Предлагаю взглянуть на проблемы под другим взглядом и чуть шире. Процессы могут быть автоматизированы до различной степени.
- Ручной труд - нет автоматизации, вы руками проделываете всё, собираете шишки и понимаете, как выглядит процесс и какие в нем бутылочные горлышки.
- Механизация - первые попытки упростить себе жизнь. Статья в confluence с собранными шишками превращается в скрипт автоматизирующий отдельные проявления рутины. Но требующий человека для принятия решений.
- Автоматизация - “Слава роботам”(с) Бендер. Человек задействован минимально, появляются различные * as Service и позволяют другим людям автоматизировать их работу.
Когда эволюционировать и переходить на следующий уровень автоматизации, а когда нет?
- Проблема огромная, автоматизируется легко - надо делать. Заведение пользователей замечательно заменяется интеграцией, например, с LDAP и решает проблемы на корню. Инструкция -> скрипт -> LDAP.
- Проблема маленькая, автоматизируется легко - имеет смысл, т.к. на дальней дистанции можно переиспользовать наработки и не изобретать велосипед по новой, ваше знание сохранено и со временем может перерасти в сервис. Если посмотреть на AWS, то предоставляется множество * as Service на любой вкус, а ведь когда-то оно тоже могло начинаться с простого скрипта. Например, я завел приватный репозиторий, где хранятся такого рода скрипты.
- Проблема маленькая, автоматизируется сложно - скорее нет. Но для кого-то даже такое редкое действие как обновление подписи к email может быть актуально, у нас на дружественном проекте такое разрабатывают; говорят, что у одного крупного аутсорсера есть специальный web портал на котором можно получить свою подпись.
- Проблема огромная, автоматизируется сложно - скорее да, если ваши договоренности представлены в виде кода, то когда настанет *ОПА(а это неизбежно, т.к. всё стремится к хаосу!), у вас будет возможность отрефакторить код.
По мере развития инфраструктуры, договоренности формализуются в виде кода и стремятся стать * as Service.
Инфраструктуру можно и нужно рефакторить. Но не всегда
Со временем инфраструктура обрастает договоренностями, стремится к хаосу. Изначально планировали одно, но реальность внесла свои коррективы, увеличив дистанцию между идеальной моделью и тем что получилось. Итогом, у вас может появиться потребность и/или желание пере структурировать это. Причины для этого могут быть совершенно разнообразные:
- Разобраться как оно работает и удовлетворить собственное эго.
- Ускорить внесение изменений.
- Уменьшить количество падений сервисов
- …
Ansible: Миграция конфигурации 120 VM c Coreos на Centos за 18 месяцев

В моем случае, досталось в наследство самописное configuration management решение. Оно представляло инфраструктуру в виде кода, оно работало, но его поддержка было сложной, т.к. оно было хрупкой, никто не хотел его поддерживать. Планомерным итогом стала замена его на Ansible, подробности можно глянуть тут Ansible: Миграция конфигурации 120 VM c Coreos на Centos за 18 месяцев. Почему 1,5 года заняла миграция? Ответ прост - 80% был reverse engineering как оно работает и только 20% непосредственно написание плэйбуков, ролей и миграция. Сам же процесс был прост:

- Сформировать список серверов.
- Выбрать сервер из списка не перенесенных.
- Зафиксировать текущие договоренности.
- Разобраться как работает.
- Описать в виде кода.
- Вернуться на пункт №2.
Как начать тестировать Ansible, отрефакторить проект за год и не слететь с катушек

На дружественном проекте занялись автоматизацией развертывания окружений у заказчиков и делали это через Ansible. Но спустя какое-то время пришло понимание, что получившиеся плэйбуки страшно запускать на боевых серверах, т.к. нет уверенности что они не свалятся с ошибкой. Ситуацию еще усугубляло то, что до клиентов был air gap(инженеру могло потребоваться прийти на площадку к заказчику где нет интернета). Задача была стабилизировать плэйбуки и наладить процесс выпуска. Как решали можно почитать в Как начать тестировать Ansible, отрефакторить проект за год и не слететь с катушек, но если кратко:
- Составить список существующих ролей.
- Выбрать одну роль.
- Покрыть тестами и зафиксировать текущие договоренности.
- Внести правки в плэйбуки/роли, исправив причины падения.
Как реализовано тестирование Ansible ролей?

Так исторически сложилось, что использовался репозиторий в котором лежали все роли. Был создан Jenkins Pipeline, который:
- Вычитвает конфиг из репозитория что тестировать.
- Генерирует динамически стадии для Jenkins.
- Запускает lint для всех ролей и плэйбуков.
- Запускает molecule для всех ролей
Реафаторинг IaC

Мы то с вами помним, что инфраструктура эволюционирует и формализуется в скрипты и/или множество * as Service. А с этим можно работать как с кодом и переиспользовать практики по рефакторингу кода. Из предыдущих сценариев выбивается нечто общее:
- Определяем измеримую цель.
- Проверяем наличие нужных знаний и времени на изменения.
- Выбираем маленький кусочек инфраструктуры.
- Разбираем что он делает.
- Формализуем договоренности и покрываем их тестами.
- Отдыхаем(это важно! иначе сгоришь оставив недоделанным работу).
- Повторяем.
И это по сути своей то же самое что и рефакторинг кода. Только со своей спецификой: несовершенный тулинг, нет синтаксического сахара, выглядит странно. Здесь так же необходимо что бы у вас было:
- Цель - без понимания куда и зачем идти, как это изменить вы не сможете измерить результат, понять когда пора остановиться.
- Время - без выделения и планирования времени на эту активность, всё может закончиться через пару итераций, не дойдя до логического завершения.
- Знания - бездумное внесение изменений может увеличить энтропию, привнести хаос который мы пытаемся структурировать.
Ускоряем ускорение

Со временем, внесение изменений в договоренности, в IaC может замедлиться и это нормально. Долго думал, как формализовать договоренности, и пришла идея изобразить историю развития проекта в цифрах и поискать закономерности. На график изображено:
- Синяя линия - Количество строк в YML файлах. Сложно померить договоренности, но можно допустить, что кол-во виртуальных машин коррелирует с ними.
- Красная заливка - Количество тестируемых Ansible ролей и плэйбоуков.
- Маджентовая линия - Количество инженеров поддерживающих и улучшающих инфраструктуру.
По графику можно увидеть, что:
- Количество кода растет линейно и прогнозируемо.
- Количество тестов отложенное коррелирует с количеством кода и растет по экспоненте.
- Количество инженеров константно.
Напрашивается вывод, что если бы не тесты инфраструктуры, то не получилось бы поддерживать рост инфраструктуры тем же количествов людей. Тесты на инфраструктуру удешевляют/ускоряют ее изменения.
Используй IaC testing pyramid. Не откладывай не потом!

Годом ранее на DevopConf рассказывал Что я узнал, протестировав 200 000 строк инфраструктурного кода и подробно рассмотрел пирамиду тестирования инфраструктуры. Ровно таже идея, что в разработке, но для инфраструктуры: идем от дешевых быстрых тестов, которые проверяют простые вещи, например отступы, к дорогим полноценным тестами разворачивающих цельную инфраструктуру.
- Static Analysis - Статистический анализ кода, без запуска. Линтеры, например.
- Unit - IaC должна состоять из простых кирпичиков и вот их тестируем. В случае Ansible это роли тестируемые при помощи Molecule.
- Integration - Очень похожи на unit, но представляют комбинацию ролей описывающих целевую конфигурацию сервера.
- E2E - Цельная инфраструктура, состоящая из множества серверов.
Когда начинать писать тесты?
Ок, договоренности в инфраструктуре можно представить как код. А потом можно рефакторить. А если есть тесты, то еще и не закопаться в рефакторинге. Но вот вопрос, когда начинать писать тесты? Рассмотрю пару проектов.
Проект №1

Начали с интеграционных тестов, и оно задалось тяжко т.к. поддерживать сложно, работают медленно. В итоге было принято волевое решение начать с основ, с линтинга и только потом юнит тестов.
Проект №2

На другом проекте рефакторинг начался с линтинга и весьма бодро пошёл. Но и кодовая база была скромная.
Вынесенный урок, что перевернутая пирамида тестирования не работает и с тестами не надо затягивать. Можно ориентироваться на такие цифры SLOC:
- 2000 - линтинг должен быть.
- 4000 - пора делать юнит тесты
- 6000 - время интеграционных тестов.
- 8000 - E2E тесты мерещат на горизонте.
Lessons learned
- Инфраструктура стремится с хаосу.
- Agreements as Сode внедрять нельзя забить.
- Ручной труд -> Механизация -> Автоматизация.
- Инфраструктуру можно и нужно рефакторить. Но не всегда.
- Тесты на инфраструктуру удешевляют/ускоряют ее изменения.
- Используй IaC testing pyramid. Не откладывай не потом!
Links
- Slides
- Video
- English Version
- Cross posrt
- A list of awesome IaC testing articles, speeches & links
- Что я узнал, протестировав 200 000 строк инфраструктурного кода
- Как начать тестировать Ansible, отрефакторить проект за год и не слететь с катушек
- Ansible: Миграция конфигурации 120 VM c Coreos на Centos за 18 месяцев
- Как наломать велосипедов поверх костылей при тестировании своего дистрибутива для SDS схд
- Podcast nsfw.co.in/04 Agreements as Code