Lev Goncharov
Infrastructure simplifying engineer
How to test your own OS distribution
Date: 2019-01-21
It is text version of speech at Devopsdays T-systems 2018-03-02 and Hashicorp meetup 2018-02-08.
Let’s imagine that you are developing software and hardware appliance. The appliance consists of custom OS distributive, upscale servers, a lot of business logic, as a result, it has to use real hardware. If you release broken appliance, your users will not be happy. How to do stable releases?
I’d like to share my story how we dealt with it.
Proof of concept
If you don’t know a goal it will be really hard to whip through the task. The first deploy variant was looked like bash:
make dist
for i in a b c ; do
scp ./result.tar.gz $i:~/
ssh $i "tar -zxvf result.tar.gz"
ssh $i "make -C ~/resutl install"
done
The script was simplified just to show the main idea: there was no CI/CD. Our flow was:
- Built on developer host.
- Deployed to test environment for a demo.
At the current stage the knowledge how it was provisioned, all known kludges were dirty magic inside developers minds. It was a real issue for us because of team growth.
Just do it
We had used TeamCity for our projects & gitlab hadn’t was popular, so we decided to use TeamCity. We manually created a VM. We were running tests inside the VM.
There were some steps in build flow:
- Install some utilities inside manually prepared environment.
- Check that it works.
- If it’s ok, then publish RPMs.
- Update staging to the new version.
make install && ./libs/run_all_tests.sh
make dist
make srpm
rpmbuild -ba SPECS/xxx-base.spec
make publish
We received a temporary result:
- Something runnable was in the master branch.
- It worked somewhere.
- We could detect some casual issues.
Do you feel the smell?
- There was a dependency hell with RPMs.
- Everyone had his own pet development environment.
- The tests were running inside the unknown environment.
- There were three completely unbounded entities: OS build, installations provision & tests.
Reduce dirty magic
We changed the flows & process:
- We had created RPM meta package & removed dependency hell.
- We created a development VM template via vagrant.
- We moved bash scripts into ansible.
- On one hand, we created an integration tests framework, but on the other hands, we used serverspec.
As a result for the current stage we received:
- All our development environment were identical.
- App code & provision logic were synced with each over.
- We speeded up new developers onboarding process.
On one hand, a build was really slow(about 30-60 minutes), but on the other hand it was good enough & successfully catch the vast majority of the issues before manual quality assurance. However we faced new different problems, i.e. then we updated the kernel or then we rolled back a package.
Improve it
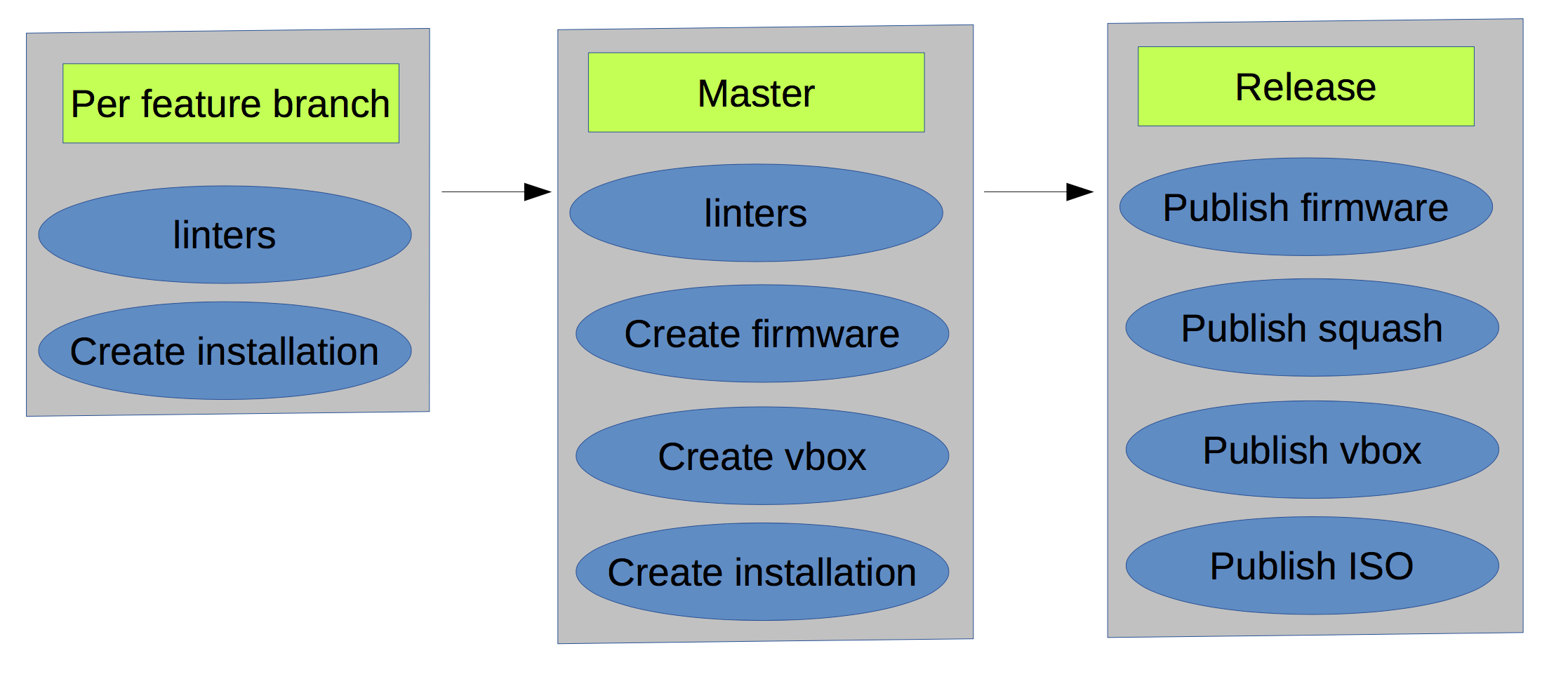
We solved a lot of different issues:
- Integration tests worked slower and slower because the dev VM template was older than actual RPMs. We were rebuilding the template manually, then we decided to automate it:
- Create a VMDK automatically.
- Attach the VMDK to a VM.
- Pack the VM & upload to s3.
- In case of a merge, it was not possible to get build status, as a result, we moved to gitlab.
- We used to do a manual release every week, we automated it.
- Auto increment version.
- Generate release notes based on closed issues.
- Update changelog.
- Create merge requests.
- Create a new milestone.
- We moved some steps into docker(lint, run some tests, send messages, build docs etc).
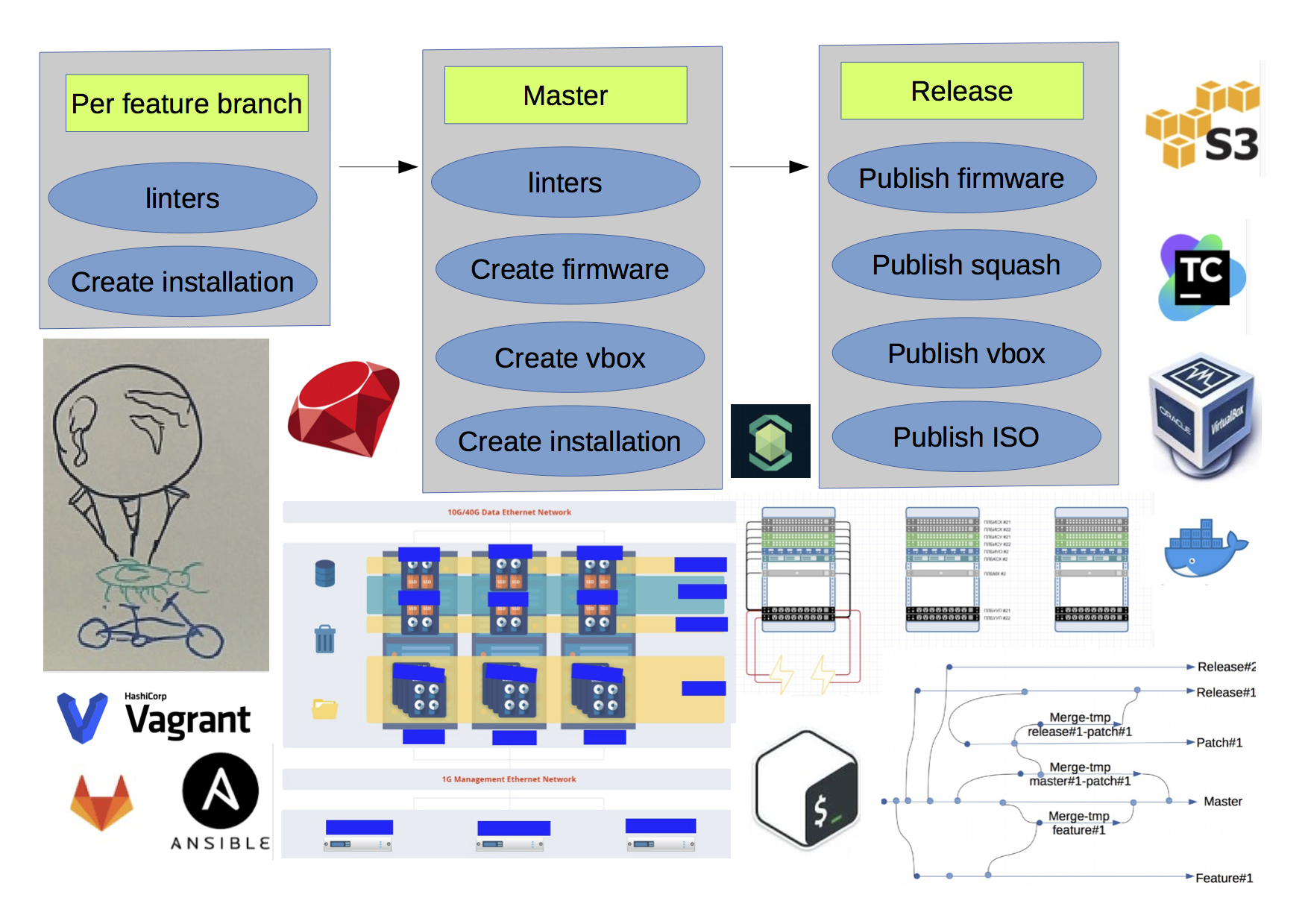
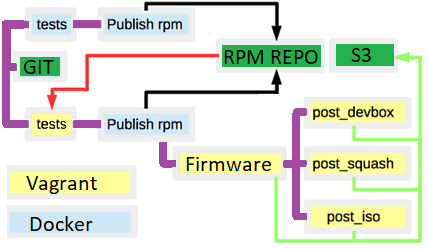
As a result at the current stage scheme looked like:
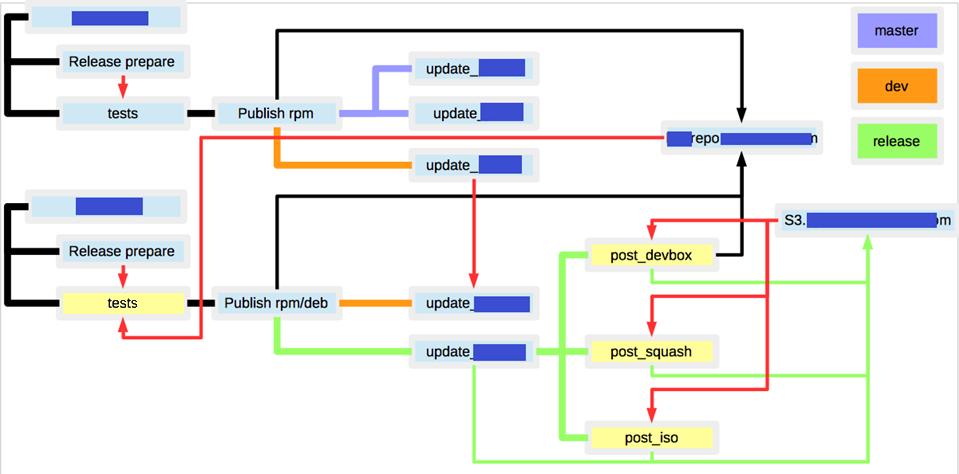
- There were a lot of RPM/DEB repos for packages.
- There was s3 as artefacts warehouse.
- If you ran a build twice for the same branch, you would receive a different result, because the meta package dependencies were not hardcoded.
- There were unobvious bounds (red coloured lines) across the builds.
However, we were able to produce release every week & improve development velocity.
Conclusion
The result was not ideal, but a journey of a thousand li starts with a single step(c).